11.Transakcijas strukturētā modelī
Iepriekš mēs aplūkojām strukturēšanu vienīgi kā līdzekli, lai lielu biznesa procesu saskaldītu pa līmeņiem, kur katram līmenim atbilstošie biznesa procesi ir relatīvi nelieli. Taču patiesībā strukturēšana nes arī zināmu semantisku slodzi attiecībā uz transakcijām.
Un, proti, tiek uzskatīts, ka ne tikai augšējā līmeņa biznesa process definē transakciju, bet arī katrs zemāka līmeņa biznesa process definē savu transakciju, kas ir apakštransakcija iepriekšējo līmeņu transakcijām. Par transakcijas vārdu vienmēr tiek uzskatīts tā biznesa procesa vārds, kas definē doto transakciju.
Augšējā līmeņa transakcija, kas atbilst primāram uzdevumam, tiek definēta tāpat kā 10. nodaļā, pieņemot, ka apakšuzdevumi ir grafiski aizstāti ar to biznesa procesu diagrammām līdz tiek sasniegts elementāro uzdevumu līmenis. Tiesa, šeit ir jābūt nedaudz uzmanīgam: teorētiski ir iespējams, ka augšējā līmeņa transakcijas sākums - ārējais uzdevums vai taimers - nav atklāti parādīti augšējā līmeņa biznesa procesa diagrammā, tie parādās tikai attiecīgo apakšuzdevumu detalizācijās. Šajā gadījumā augšējā līmeņa transakcija "nepratīs" automātiski startēt, šis starts ir atklāti jānorāda zemākā līmeņa uzdevumā ierakstot
START <transaction name>.
Paskaidrosim šo situāciju ar piemēru.
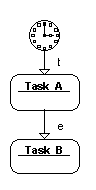
Zīm. 11.1. BP primārajam Task_W un apakšuzdevumam Task_A ar taimera referenci
Zīm. 11.1 attēlotajā gadījumā augšējā līmeņa transakcija Task_W startēs automātiski. Taču, ja strukturēšana ir izdarīta atbilstoši Zīm. 11.2, tad augšējā līmeņa transakcija automātiski nestartēs, tas ir jānorāda attiecīgā zemāka līmeņa uzdevumā, kā tas šajā zīmējumā parādīts.
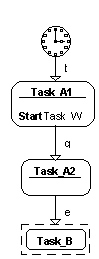
Zīm. 11.2. BP primārajam Task_W un apakšuzdevumam Task_A ar atklātu transakcijas startu
Šis pats transakcijas automātiskā sākuma princips attiecas arī uz strukturēšanas zemākajiem līmeņiem. Vienīgā atšķirība par transakcijas automātisko sākumu strukturēšanas zemākos līmeņos ir sekojoša: transakciju sāk ne tikai notikumi, kas ienāk no taimeriem un eksternāliem uzdevumiem, bet arī notikumi (un tas ir visraksturīgākais gadījums attiecībā uz apakšuzdevumiem!), kas ienāk no referencēm uz kaimiņuzdevumiem. Protams, lai transakcija sāktos, visiem notikumiem, kas rada attiecīgā trigerēšanas nosacījuma izpildi, ir jānāk no minētajiem ārējiem avotiem.
No teiktā seko, ka viens un tas pats zemākā līmeņa uzdevums var piedalīties vairākās savstarpēji iekļautās transakcijās, t.i., šajā uzdevumā ienākošiem un izejošiem notikumiem var būt vienlaicīgi pierakstīti vairāku transakciju TID. Tas nozīmē, ka AND tipa trigerēšanas nosacījums izpildīsies tikai tad, kad ieejošiem notikumiem ne tikai zemākā līmeņa, bet arī visu iepriekšējo līmeņu TID sakritīs.
Attiecīgā līmeņa transakcija beidzas, ja dotajā biznesa procesā vairs nav notikumu ar dotās transakcijas TIDu. Transakciju var nobeigt arī vardarbīgi, pierakstot pie uzdevuma (vai tā zarojuma simbola)
END <transaction name>.
Kā jau mēs iepriekš atzīmējām, ar transakcijas vārdu šeit tiek saprasts biznesa procesa vārds, kurš rada šo transakciju.
Notikumam izejot ārā no dotā biznesa procesa tiek dzēsts transakcijas TIDs, ko radīja šis biznesa process.
Notikuma TIDu var dzēst arī vardarbīgi pierakstot pie izejas notikuma NOTID, šajā gadījumā dotajam notikumam tiks nolikvidēts zemākā līmeņa TIDs.
Dažreiz strukturēšana tiek veikta tikai aiz tīri tehniskiem apsvērumiem un līdz ar to zemāka līmeņa biznesa procesiem var arī nebūt saturīga jēga. Šajos gadījumos mēs varam gribēt, lai dotais biznesa process neradītu transakciju, kas savukārt iespaido AND tipa trigerēšanas nosacījumus. Šādas nevajadzīgas transakcijas rašanos mēs varam novērst pie visiem iespējamiem transakcijas sākuma uzdevumiem pierakstot NOSTART.
Transakcijas jēdziens un ar to saistītās sintaktiskās konstrukcijas līdz ar to ir izklāstītas.
Noslēgumā vēl daži vārdi par datu objektu dzīves ilgumu. 2. nodaļā mēs teicām, ka datu objekts ir kāda uzdevuma radīts objekts, kas "dzīvo" tikai vienas transakcijas laiku. Šis skaidrojums ir pietiekoši precīzs gadījumam, kad ir tikai viena līmeņa transakcija - šis gadījums aprakstīts 10. nodaļā. Taču strukturēšanas gadījumā, kad parādās vienlaicīgi savstarpēji iekļautas transakcijas, iepriekš minētā datu objekta dzīves ilguma definīcija prasa papildus skaidrojumu. Mēs to šeit izlaidīsim, jo intuitīvā izpratne katrā konkrētā gadījumā parasti sakritīs ar formālo definīciju.
12. GRAPES-BM un datu plūsmu modelēšana
Viena no plašāk lietotajām sistēmu būves metodoloģijām ir t.s. strukturētas būves (structured development) metodoloģija (DeMarco, T. Structured Analysis and Specification. Yourdon Press, 1978; Gane, C. and Sarson, T. Structured Systems Analysis. Prentice Hall, 1979). Šī metodoloģija lielā mērā balstās uz datu plūsmu modelēšanu - sākot ar sistēmu pašu augšējo līmeni un beidzot ar pašu zemāko - programmatūras struktūru.
Datu plūsmu modelēšanai tiek izmantotas t.s. datu plūsmas diagrammas (data flow diagram - DFD).
Name |
Data flow diagram symbols |
GRAPES-BM BP diagram symbols |
| Process, function |
|
|
| Data store |
|
|
| External entity |
|
|
| Data flows |
|
|
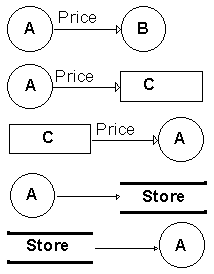
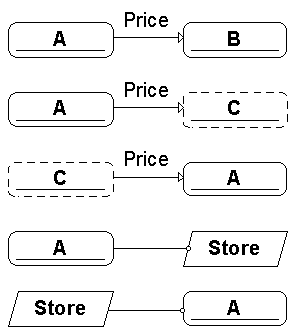
Zīm.12.1. Apzīmējumi datu plūsmas diagrammās un atbilstošie BP simboli |
||
Šīs nodaļas mērķis ir parādīt, kā datu plūsmas diagrammas iekļaujas valodā GRAPES-BM. Tradicionālās datu plūsmas diagrammas satur četru tipu elementus: procesus (jeb funkcijas), datu noliktavas, datu plūsmas un ārējās entītes (external entities). Viens no tradicionālākajiem (DeMarco) šo elementu grafiskajiem apzīmējumiem ir parādīts Zīm. 12.1 vidējā kolonnā. Šī paša zīmējuma labajā kolonnā ir parādīti semantiski atbilstošie valodas GRAPES-BM grafiskie simboli. Šie simboli tiek izmantoti konstruējot BP diagrammu, kura šajā gadījumā atbilst datu plūsmas diagrammai.
Zīm. 12.2 ir attēlota vienkārša datu plūsmas diagramma lietojot tradicionālos simbolus.
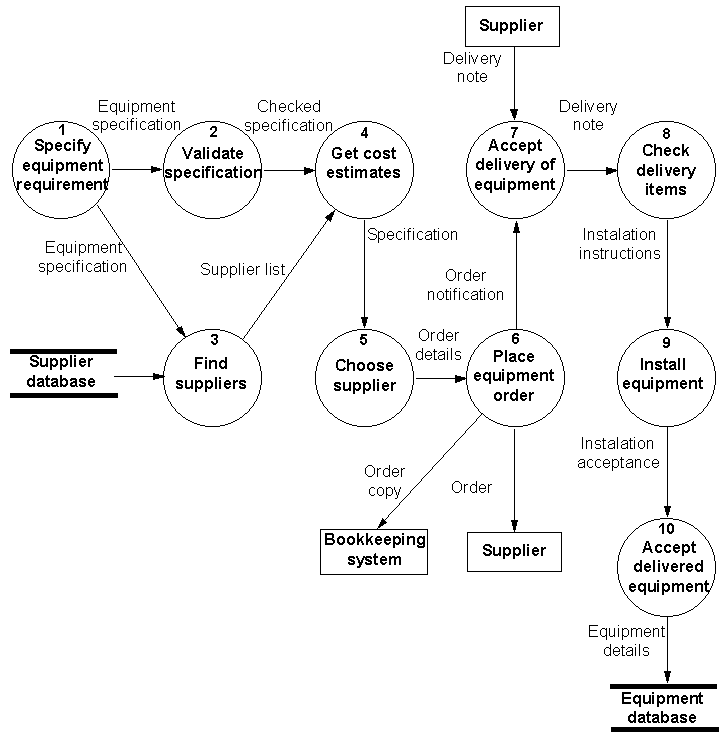
Zīm. 12.2 Piemērs datu plūsmas diagrammai
Zīm. 12.3 šī pati diagramma ir attēlota GRAPES-BM BP diagrammas izskatā. Kā redzams, atbilstība ir pilnīga.
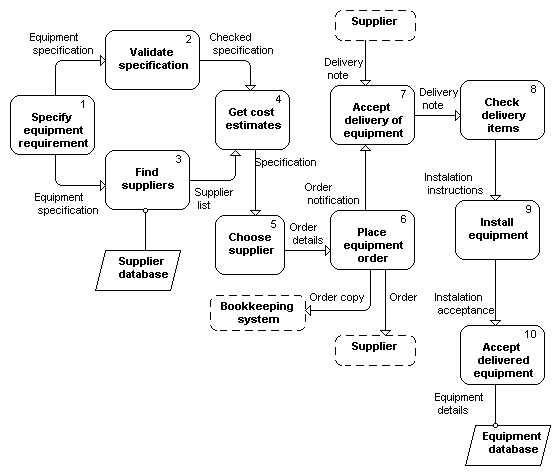
Zīm. 12.3. Datu plūsmas attēlojums ar BP diagrammu
Tradicionālajām datu plūsmas diagrammām ir paredzētas arī strukturēšanas iespējas. Zīm.12.4 ir attēlots Zīm. 12.2 redzamās funkcijas Place equipment order izvērsums atbilstoši tai sintaksei, kādu parasti lieto datu plūsmas diagrammu gadījumā.
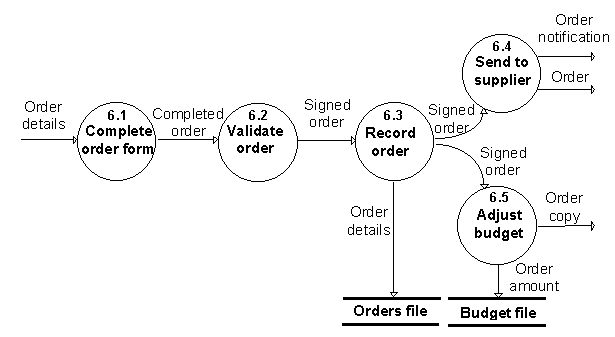
Zīm. 12.4. Vienas funkcijas izvērsums DFD diagrammā
Zīm. 12.5 šis pats izvērsums ir attēlots atbilstoši GRAPES-BM sintakses prasībām. Kā redzams, valodā GRAPES-BM tiek precīzāk aprakstīts izvērsuma interfeiss - references uz dotās funkcijas (uzdevuma) “apkārtni” iepriekšējā līmeņa diagrammā.

Zīm. 12.5. Vienas funkcijas izvērsums BP diagrammā
Datu plūsmas diagrammu gadījumā parasti zīmē arī t.s. konteksta diagrammu (Zīm. 12.6). Equipment procurement system ir sistēma, kuras izvērsums ir attēlots Zīm. 12.2.
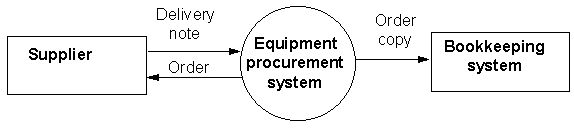
Zīm. 12.6. Datu plūsmas konteksta diagramma
GRAPES-BM gadījumā šī konteksta diagramma ir jāzīmē kā augšējā līmeņa BP diagramma (Zīm. 12.7).
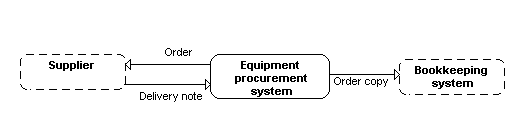
Zīm. 12.7. Konteksta diagramma BP formā
Šajā gadījumā pirmā līmeņa diagramma, kas atbilst Zīm. 12.3, vairs nebūs augšējā līmeņa BP diagramma, tā būs diagramma, kas seko aiz Zīm. 12.7 attēlotās diagrammas, tādēļ ārējās entītes šajā diagrammā jau būs jāattēlo kā references:
![]()
Valodā GRAPES-BM ir iespēja precīzāk raksturot aplūkojamo uzdevumu: var norādīt izpildītāju, izpildes laiku (duration) un tml. Šīs papildiespējas ir noderīgas arī gadījumā, kad mēs uzdevumu lietojam datu plūsmas diagrammas kontekstā. Var lietot arī trigerēšanas nosacījumu, ja mēs precīzāk gribam norādīt uzdevumu izpildes secību. Tādā veidā datu plūsmas diagrammu mēs varam pārvērst par biznesa procesu.
Tomēr pastāv būtiskas nianses, kas atšķir datu plūsmas diagrammas no biznesa procesiem.
Pirmkārt, tā ir metodoloģija:
Tālāk, pastāv arī semantiskas atšķirības:
tad tas nozīmē, ka darbība B kaut kādā veidā (kādā - atkal parasti ir skaidrs no darbības B saturīgā apraksta) izmanto darbības A rezultātus, pie tam šie rezultāti var attiekties kā uz vienu darbības A izpildes reizi, tā arī tie var būt summāri pa vairākām darbības A izpildes reizēm. Datu plūsmas vārds ddd dotajā gadījumā ir nevis notikuma vārds, kā biznesa procesa gadījumā, bet gan to rezultātu vārds, kurus uzdevums A “nodod” uzdevumam B, vai arī uzdevums B “paņem” no tās rezultātu kaudzītes, ko ir izstrādājis uzdevums A.
Līdz ar to biznesa modelēšanā pieņemtais datu plūsmas mehānisms notikumu formā ir tikai viens no iespējamiem datu plūsmas veidiem.
Ņemot vērā iepriekš teikto, kolīzijas var radīt plūsmas bultiņa bez vārda - biznesa procesa gadījumā tā ir vadības plūsma, datu plūsmas diagrammas gadījumā tā ir vienkārši norāde, ka viens uzdevums izmanto otra uzdevuma darbības rezultātus. Tādēļ, lai izvairītos no šādām kolīzijām, ir ieteicams datu plūsmas gadījumā plūsmas bultiņām (kuras grafiski izskatās tāpat kā notikumu plūsmas bultiņas) vienmēr likt vārdus, ar kuru palīdzību tiek sīkāk specificētas attiecīgās plūsmas.